家用宽带连接北邮人 ipv6 PT
众所周知(?),北邮人等一众教育网 PT 是只支持 ipv6 的。一般情况来说,家用宽带是无法正常连接的。这篇博文我会记录一下我是怎么绕过各种限制连接上北邮人 PT 的。
回溯法中的 DP 陷阱
今天在做 leetcode 每日一题 140. 单词拆分 II,遇到一个很有意思的问题。使用同样的转移方程,自顶向下可以通过,自底向上却超时。自顶向下的过程中实际会产生更多的剪枝,从而减少计算量。
配置 wasm 开发环境笔记
今天在配置 wasm 环境,把安装步骤中遇到的问题写一下。
环境配置部分
安装
wasm-packCLI 工具:cargo install wasm-pack由于
wasm-pack会在运行时安装wasm-bindgen,这一步由于国内的网络环境很慢,可以提前手动安装:cargo install wasm-bindgen-cli注意这里要跟
Cargo.toml里面的版本号一致。在编译完成后,
wasm-pack默认会使用wasm-opt工具进行大小优化,而这个工具也是运行时下载安装的。如果要挂代理,需要手动设置环境变量,并 在管理员权限下运行一次wasm-pack以安装wasm-opt工具:> $env:HTTPS_PROXY="http://192.168.31.157:1080" > wasm-pack build
开发部分
将 wasm 项目加入 node 项目的依赖:
# package.json
{
"dependencies": {
"utils": "file:../utils/pkg"
}
}在 js 中引入:
// 编译时引入
import * as utils from "utils";
// 运行时引入
import("utils/utils.js").then(utils => utils.foo());力扣杯竞赛题解
本篇博文对 2020 年 9 月 12 号的乐扣杯个人竞赛进行题解。
Nginx rewrite 匹配部分消失的解决办法
昨天在配置 nginx 的时候遇到一个神奇的问题,见如下 nginx 配置:
map $http_accept_language $locale {
default "en-US";
~*en "en-US";
~*zh "zh-CN";
}
location / {
rewrite ^/(.*)$ /prerendered/$locale/$1;
}
如果 header 中的 Accept-Language 没有匹配成功,走到 default,$1 就可以正常地匹配 rewrite 部分的uri;但是如果其成功匹配到 en 或是 zh 时,这个 rewrite 部分的 $1 就神奇地消失了。
我在 StackOverflow 上询问之后,Richard Smith 对这个现象进行了解答:
数字(匹配组)会被最近的一次正则匹配所覆盖,当 rewrite 匹配成功后,由于懒计算,$locale 会尝试匹配;如果匹配成功,rewrite 部分的匹配组就会被覆盖成空串。
解决方法有两种:
- 使用命名匹配组,
rewrite ^/(?<myuri>.*)$ /prerendered/$locale/$myuri last; - 使用
$uri变量,rewrite ^ /prerendered/$locale$uri last;
在这里感谢 Richard!
Windows 下安装 diesel cli
1. SQLite 安装
- SQLite 网站下载预编译二进制,解压到譬如
C:\lib。 - 通过
.dll、.def文件转换出.lib文件:- 找到 VS 安装目录下的
lib.exe,我的在C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.26.28801\bin\Hostx64\x64\lib.exe。 - 运行
lib.exe /DEF:sqlite3.def
- 找到 VS 安装目录下的
- 设置环境变量:
$env:SQLITE3_LIB_DIR="C:\lib\"
2. Postgres 安装
- 安装 postgres
- 设置环境变量:
$env:PQ_LIB_DIR="C:\Program Files\PostgreSQL\12\lib"
3. Diesel 安装
cargo install diesel_cli --force --no-default-features --features "postgres sqlite"attack lab rtarget 2
这是 attack lab 最后一个,也是最难的一个问题。我们需要利用 start_farm 到 end_farm 之间的函数带一个字符串参数调用 touch3 函数。
还是同样,先利用 python 分析这些函数中有哪些可利用的 gadgets。通过去重,我得到下面的 gadgets:
attack lab rtarget 1
本文中全部代码都可以在我的 GitHub https://github.com/gwy15/csapp-lab 中找到。
rtarget 跟 ctarget 相比,难度提高了不少:
- 使用了栈随机化,导致无法确定溢出区的地址,插入代码也无法确定跳转地址。
- 标记栈区域的内存为“不可执行”,从而避免了执行插入缓存区的代码。
但是即使这样,缓冲区溢出依然具有被攻击的可能性。
attack lab ctarget 3
phase 3 跟 phase 2 基本上一样,汇编代码:
leaq 0x8(%rsp), %rdi #
ret这里,我们将 char* sval 放在 touch3 的地址上方,并将 rdi 寄存器设置为 rsp+8 以拿到其地址。

attack lab ctarget 2
ctarget 第二个任务是进入代码 touch2,而且需要带参数(第一个参数设置为 0x59b997fa)。
这里我们需要插入可执行代码,并将控制权跳转到可执行代码,设置 rdi 寄存器,再跳转到 touch2。
同样考虑栈结构(ctarget 没有开启 栈随机化),因此运行时栈的地址是确定的:

attack lab ctarget 1
ctarget 的第一个任务是通过缓冲区溢出,进入代码 touch1。
首先使用 objdump -d -s ctarget > ctarget.asm 导出 ctarget 的汇编代码。观察代码调用关系,可以发现调用链条为:
main -> stable_launch -> launch -> test -> getbuf -> Gets -> getc
其中,getbuf 里定义了一个栈上的缓冲区,并将其指针传递给了 Gets(而没有传递缓冲区的大小),因此 Gets 中存在溢出危险。
Python 的菱形继承和 MRO
Python 是一门(在我看来很不幸地)支持多继承的语言。既然支持了多继承,那难以避免的一个问题就是菱形继承。考虑下图的类关系:

火锅捞蛋
今天逛 v2ex 看到一个挺有意思的问题:
假如我去吃火锅,已知锅里有 N 个鹌鹑蛋,我想要把这些蛋捞来吃。每个蛋被捞到的概率均为 P ,并且一次捞出的个数没有限制。但是,如果我连续 T 次都一个没捞到,那我就会放弃。
问题:当我放弃后,锅里剩下的鹌鹑蛋的个数的期望 E 是多少?(可以假设 N=10, P=0.2, T=5 )
这道题如果是做算法题的话,很容易想到用 DP 解,定义状态 表示在锅中还剩 个蛋并且已经白给了 次后,锅中剩下的蛋的个数。
显然,从状态 可以转换到 (又白给)、(捞起来 个,其中 )。
设 为状态 剩下的蛋的期望,有转移方程:
记一道 LeetCode 的优化过程
问题背景
LeetCode 126. 单词接龙 II
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
函数签名:
pub fn find_ladders(begin: String, end: String, word_list: Vec<String>) -> Vec<Vec<String>>这道题的思路还是很清晰的,先从 word_list 构建出一个无向图,然后 BFS 找最短路,再反向构造路径即可。
但当我写完提交后,我却震惊地发现,我的 Rust 代码运行时间(248ms)甚至比其他人的 python 还长。这当然说明代码中存在不小的问题,可能是某个地方复杂度爆炸了,需要解决。
二叉树的 morris 遍历
1. 背景介绍
对于二叉树,常用的遍历方式有前序遍历、中序遍历、后序遍历。借由 DFS 算法,我们可以在 O(n) 时间内、使用 O(h) 的空间完成遍历。这通常没什么问题,但如果有特殊要求 O(1) 的空间,那可以采用 Morris 遍历算法。
Morris 遍历算法可以在 O(n) 时间内使用 O(1) 的空间完成遍历,但需要对二叉树进行修改(遍历完成后恢复原样)。
LeetCode 903 DI 序列的有效排列
我们给出 S,一个源于 {'D', 'I'} 的长度为 n 的字符串 。(这些字母代表 “减少” 和 “增加”。) 有效排列 是对整数 {0, 1, ..., n} 的一个排列 P[0], P[1], ..., P[n],使得对所有的 i:
如果 S[i] == 'D',那么 P[i] > P[i+1],以及;
如果 S[i] == 'I',那么 P[i] < P[i+1]。
有多少个有效排列?因为答案可能很大,所以请返回你的答案模 10^9 + 7
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/valid-permutations-for-di-sequence 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
使用 Docker 在 Windows 上搭建 Seafile 私有网盘
Seafile 的 官方文档 写得很详细,如果你使用的是 Linux 环境下的 docker,应该不存在任何问题。这片博文主要是讲 Windows Docker 下我遇到的 Seafile 私有网盘搭建过程中的问题和解决方法。
康托展开的编码、解码和全排列
对于不重复的 个数,其有 个排列。如果我们要求其中第 个排列,可以通过构造一个全排列到自然数 的双射来直接构造这个排列。
康托展开就是这样一个映射。康托展开不在意数的具体数值,只在乎其全序顺位,即在集合中排序到第几小;或者说有多少数比此数更小。
基于 docker 和 pyppeteer 的预渲染的自动化
在 上一篇博客 中,我基于 pyppeteer 实现了 vue SPA 的预渲染。但是到目前为止,预渲染还需要我每次手动在我的 Windows 电脑上操作,不能自动化进行,更不能持续集成。在这篇博客里,我将实现基于 docker 和 pyppeteer 的预渲染自动化。
使用 pyppeteer 预渲染对 vue 单页应用进行 SEO
问题背景
由于 我的博客 使用 vue 开发,是一个 SPA 单页应用,因此在不进行特殊优化的默认状态下,加载界面时只会返回一个空白 HTML 文件。在加载 HTML 文件中的 js 文件后,才会进行构建 DOM、拉取数据并显示等操作。而目前的爬虫(百度爬虫、Google爬虫等等)并不支持这种先加载 HTML 文档、后拉取数据的异步操作。这就对 SEO 带来了很大的困难。
通常来说,SPA 对此的应对办法是 ssr (服务器端渲染)或是预渲染。由于我的博客是不怎么变化的,因此预渲染应该比服务器端渲染更加符合我的要求。下面讲一下我是怎么进行预渲染的。
KaTeX 带来的布局错误与修正
前几天,我在 我的博客 中引入了 数学公式渲染功能,是使用 KaTeX 库实现的。但是引入这个库后我发现,凡是渲染了数学公式的博客,布局都会出现问题,如下图所示。

设计的布局应该只出现左边的滚动条,而由于页面高度始终为 100vh,不应该出现右边的滚动条。对于没使用公式的博文,布局都是正常的。
LeetCode 新 21 点——DP、马尔科夫链和前缀和
0. 题干
LeetCode #837 新 21 点题干如下:
爱丽丝参与一个大致基于纸牌游戏 “21点” 规则的游戏,描述如下:
爱丽丝以 0 分开始,并在她的得分少于 K 分时抽取数字。 抽取时,她从 [1, W] 的范围中随机获得一个整数作为分数进行累计,其中 W 是整数。 每次抽取都是独立的,其结果具有相同的概率。
当爱丽丝获得不少于 K 分时,她就停止抽取数字。 爱丽丝的分数不超过 N 的概率是多少?
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/new-21-game 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1. 正向计算停机概率
拿到题目,首先想到的是计算停机概率—— 定义为最终停机在和为 的概率。显然,这里有 对于题目要求的 ,显然为 。因此,我们只需要计算出停机概率 ,就可以解决这个问题。
阿里云函数计算的 bug 与 workaround
去年写的阿里云函数计算是直接用 WSGI 接口撸的,最近引入 flask 框架重构了。但是重构并在本地测试通过后,放到云上遇到了问题。函数计算会对 url 中存在非 ascii 字符的情况报错。
搭建自己的微信消息推送系统 Wechat push
服务器上跑的程序出错了想及时收到通知?对于这类业务报警/消息推送,一般的方法是使用邮件。但是邮箱配置起来较为麻烦,对于懒得配置邮箱或是嫌邮件送达率不高的程序员,微信看起来是一个更好的进行提醒推送的通道。
市面上已经有 Server 酱 或是 WxPusher 这类解决方案,利用微信服务号的模板消息进行消息推送。但很可惜,这两者都不开源,使用也有些限制,同时UI也无法自定义。对于喜欢折腾的程序员,当然是选择轮子造起来~
下面是博主搭建好的结果示意和开源库地址: 开源库 wechat-push
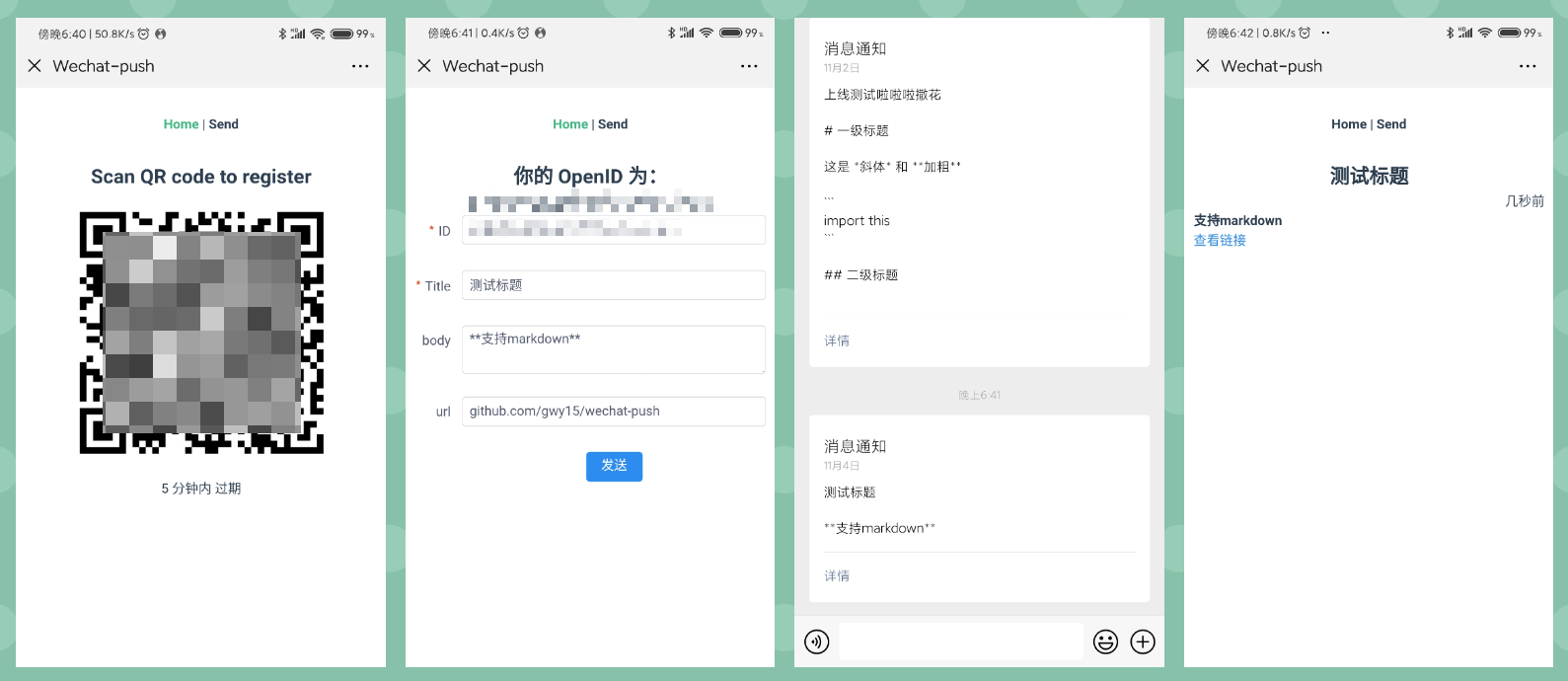
使用
遵循 RESTful 风格的代码,发送消息只需要一个请求:
POST https://domain.com/message
{
receiver: openid,
title: title,
body: optional, markdown msg,
url: optional, url at end of the body
}获取自己的 openid,访问页面 https://domain.com/ 并扫码即可。
Linux管理面板——cockpit 安装和配置
Cockpit 是一个开源 linux 软件,官网的介绍是“为你服务器准备的易用的、集成的、可扫视的、开放的网络界面”。通过 cockpit,我们可以通过网络进行(多台)服务器的管理,如审查用量、重启服务、查看 docker 等操作,省去了一些 ssh 操作。
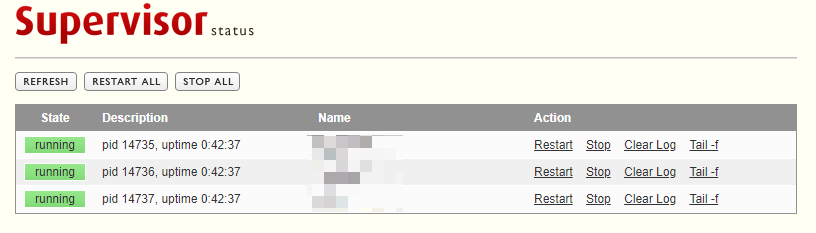
service的替代:Supervisor——配置和坑
对于一个想要长期在后台跑的服务,比如一个 web server,一般有这几种方法:
- 使用 nohup + &
- 做成一个 service,使用
sudo service <servicename> <command>控制 - 自行实现 daemon
- 利用 screen 软件,放到一个 screen 里面跑
第一个方法实用性太差;第二个和第三个在能处理好日志时不错,但是其维护起来较为麻烦;最后一个方法是笔者以前常用的方法。
supervisor 是用 python 编写的程序,其能够将非 daemon 程序放到后台运行并监控,还能做到检测到程序挂掉时重新拉起。它使用了 client/server 架构,因此提供了 web UI 以便远程控制(其实有坑)。
asyncio.CancelledError 终于是 BaseException 了
经常写 Python 异步代码的人可能都知道,当前 Python 版本(3.7.4-)中,,当一个 coro 被取消时,会抛出 CancelledError,而这个 CancelledError 定义为:
# asyncio/exceptions.py
class CancelledError(concurrent.futures.CancelledError):
"""The Future or Task was cancelled."""修改 Hexo NexT 主题的配色
Hexo 的 NexT 原来的主题是极简的黑白配色,一眼看上去还可以,但是看久了不免会有些视觉疲倦。如果想修改 hexo NexT 主题的配色应该怎么做呢?我在网上找到了一篇相关的文章。
这个文章中的修改方法的原理是修改.styl 文件(Stylus语法)中的几个大的定义。按照这个方法虽然可以修改,但是会将其他部分的颜色也一起修改了,有没有更好的、更细粒度的方法呢?
一些 Python 的 snippets
log 以天为单位分文件保存
以前我用的比较多的是 RotatingFileHandler,这个根据文件大小进行分割。有的时候我们对文件大小限制并不大,而对日期更敏感一点。这个时候可以用官方库里面的 TimedRotatingFileHandler。