记一道 LeetCode 的优化过程
问题背景
LeetCode 126. 单词接龙 II
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
函数签名:
pub fn find_ladders(begin: String, end: String, word_list: Vec<String>) -> Vec<Vec<String>>这道题的思路还是很清晰的,先从 word_list 构建出一个无向图,然后 BFS 找最短路,再反向构造路径即可。
但当我写完提交后,我却震惊地发现,我的 Rust 代码运行时间(248ms)甚至比其他人的 python 还长。这当然说明代码中存在不小的问题,可能是某个地方复杂度爆炸了,需要解决。
寻找性能瓶颈
要针对优化,首先需要找出哪个地方是算法瓶颈。仔细 review 了代码后,我把目光投向了预处理构建无向图部分。后面两个 BFS 的复杂度都是 O(n) 的,而预处理部分因为计算了两两字符串之间的距离,因此复杂度是 O(n)。
为了验证我的猜想,需要进行 profile。对于 Rust,目前没有像 C++/VS 那样好用的 profiler,因此我随便撸了一个宏:
use std::time::Instant;
macro_rules! perf {
($name:expr, { $($block:tt)* }) => {
let now = Instant::now();
$($block)*
eprintln!("Step {} took {}ms", $name, now.elapsed().as_millis());
};
}可以像这样使用:
prof!("build graph", {
// build graph
for i in 0..n {
let si = &word_list[i];
for j in 0..n {
if i != j && Self::word_dist(si, &word_list[j]) == 1 {
next[i].push(j);
}
}
}
});将几个部分都套起来,并生成了几分我认为比较合理的测试数据后,运行结果告诉我,确实是预处理的问题。对于某一个测例,BFS 花费 0ms,而预处理花费 20s。
算法优化
分析预处理部分:
我们需要将相差仅一个字符的字符串对作为边,构建一个无向图 next。像上面的算法,其时间复杂度很明显为 $O(N^2 l)$,其中,$N$ 为字符串个数,$l$ 为字符串长度。空间复杂度,不需要额外空间,$O(1)$
考虑这样一个算法:将每个字符串的每个位置都替换为 *,使用哈希表储存对应下标。这样一来,复杂度就可以变化为:
遍历每个字符串 $N$ $\times$ 遍历字符串每个位置 $l$ $\times$ (替换字符、查哈希表$l$ $+$ 处理相邻匹配结果 $d$)
其中,$d$ 为邻接矩阵的平均密度。假设字符串都是平均生成的,则其距离为 1 的字符串占总字符串空间的 因此,可以认为 $d=N p=\frac{26 N l}{26^l}$。显然这是极为稀疏的。而就算构造恶意数据,$d$ 的上界也为 $N$(与每一个字符串都相邻)。因此,当 $l \le N $,可以认为后一个算法的时间复杂度总是优于第一个。
改良后的算法时间复杂度为 $O(N l(l+d))$,空间复杂度为 $O(N l d)$。
优化结果
重构预处理部分的代码后提交结果:
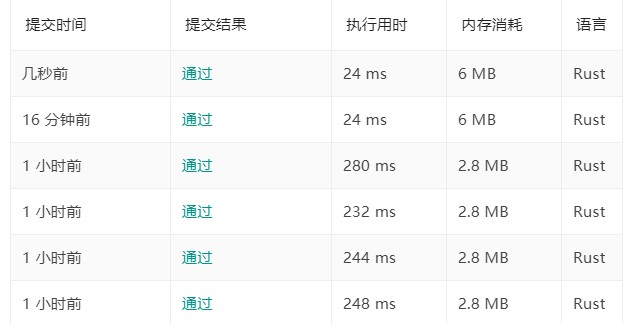
时间降为原来的 $1/10$。
